Creating the data source
Google Cloud Storage is a service for storing objects and files (eg CSV and JSON) on Google Cloud.
By adding the Google Cloud Storage connector in Kondado, you will be able to create ETLs from your files directly to your Data Warehouse or Data Lake with just a few clicks.
Adding the connector
To add the Google Cloud Storage connector, follow the steps below:
1) Login to your Google Cloud account
2) Click on this link to access the Service Accounts section, or follow the image below:
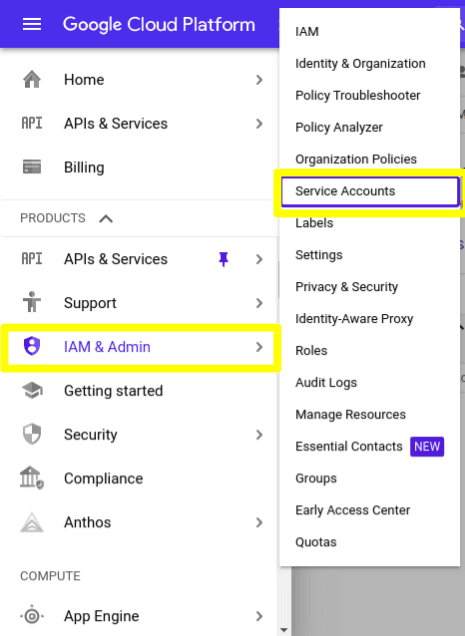
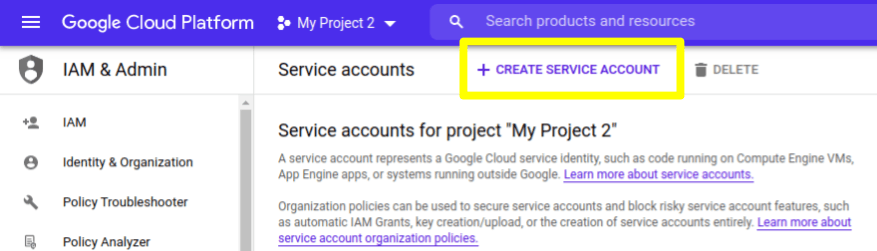
3) Once in the Service Accounts section, click on "CREATE SERVICE ACCOUNT"
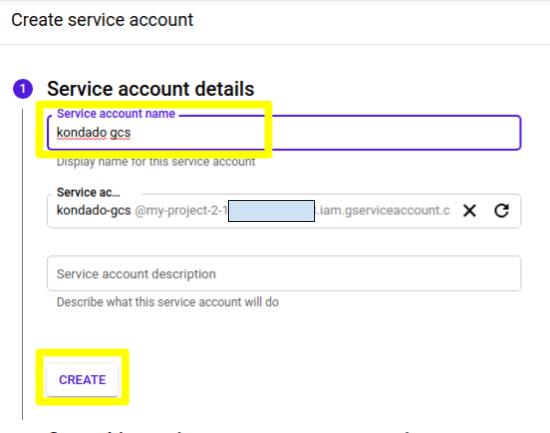
4) In the first step, fill in a name for your service account (eg "kondado gcs") and click on "CREATE"
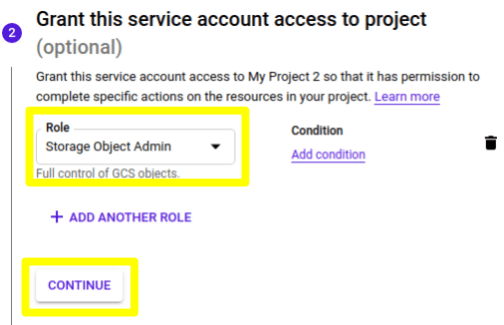
5) In the second step of the creation process, select the Role "Storage Object Admin" and click CONTINUE
6) Now just click on "DONE" to finish the creation
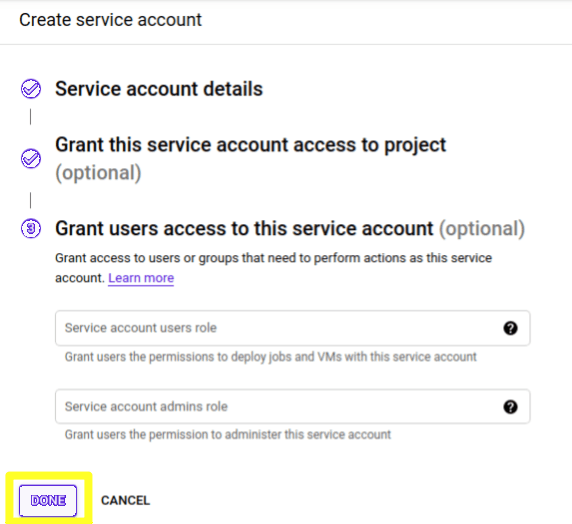
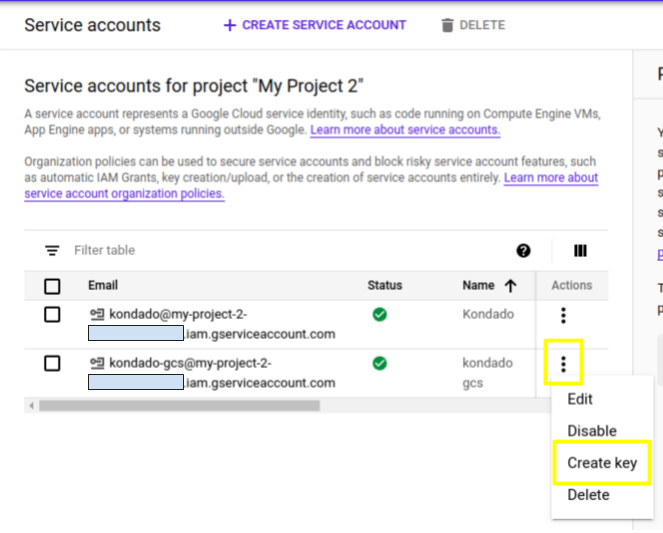
7) Once created, you will be directed to a list of all active service accounts. Locate the one you just created and, on the three vertical dots on the right, click on "Create key"
8) In the dialog, select the type "JSON" and then click on "CREATE"

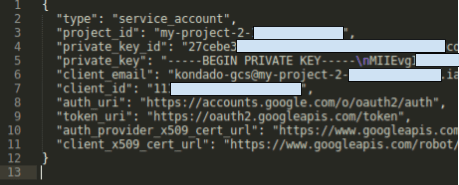
9) After clicking create, the key will be downloaded to your computer. Open the downloaded file in a text editor, it will look something like this:
10) Login to the Kondado platform, go to the add connectors page and select the Google Cloud Storage connector
11) On the add connector page, do the following:
- In "Bucket" fill in the name of your bucket
- In "JSON Credential", copy and paste the file values from step (9)

12) Now just click on "SAVE" and you will be ready to upload your files from Google Cloud Storage to your Data Warehouse or Data Lake
Pipelines
Summary
Relationship chart
Click to expand

CSV (grid output)
You can indicate the name of a file or even the beginning of the file name and we will integrate all of them. Once executed, the pipeline will save the highest change date of the files it read and, on the next run, only look for files with a later change date. In order to absorb files with different columns, the data will be pivoted on the target (one row per cell: row_number, column_number, first_column_value, value).
Replication type: Incremental
Parameters:
- File name or prefix: Use the file name or a file prefix that matches more than one file
- Field delimiter: Charachter that separates the columns (eg: comma, semi-column, pipe, etc)
- Read start date (Savepoint): Data replication initial date
Notes
- Part of this documentation was automatically generated by AI and may contain errors. We recommend verifying critical information
Connect Google Cloud Storage to Kondado
Set up a service account in Google Cloud and configure the JSON credentials in Kondado to start extracting files to your data warehouse.
Create a Google Cloud service account
Log in to your Google Cloud account, navigate to the Service Accounts section, and click CREATE SERVICE ACCOUNT. Name it (e.g., "kondado gcs") and assign the "Storage Object Admin" role.
Generate and download the JSON key
Locate your new service account in the list, open the three-dot menu, and select "Create key." Choose JSON format, then download and open the file in a text editor to copy its contents.
Add the source in Kondado
Log in to the Kondado platform, go to the add data sources page, and select Google Cloud Storage. Enter your bucket name and paste the JSON credential values into the corresponding field.
Save and start building pipelines
Click "SAVE" to finalize the connection. You can now create ETL pipelines that extract CSV or JSON files from your bucket directly to your Data Warehouse or Data Lake, with automatic incremental loading based on file modification dates.
Frequently asked questions
row_number, column_number, first_column_value, and value, plus metadata columns such as __file_basename and __kdd_insert_time.