
The quickest way to doom your data science, business intelligence, and analytics efforts is to directly use data that is in production to analyze insights.
The main causes of this are:
Format: Data in production has a format aimed at product operations, mainly INSERT and UPDATE, which is not suitable for SELECT queries in analytics.
Criticality: Analytics queries involve aggregation operations and multiple table crossings (JOIN) that are very often heavy and affect product performance, and can even “take down” the service for users, causing a bad customer experience and desperation of SREs and DevOps
Shallow analyses: you will always be consulting only one source of data, or making a mistake with pairing instead of crossing data from other services used (such as Zendesk, Adwords or Pagar.me)
ETL: Extract, Transform, Load
The concept of ETL emerged as a way to eliminate these flaws. The acronym, in English, means Extract, Transform, Load. To mean:
An ETL operation extracts data from the source (the production source), applies some transformation (formats the data for queries) and loads it into another database (destination), separate from production, which will be used only for analytics
The ETL manages to remedy the main causes of failure of your analytics efforts, as it already leaves the data in a defined format for queries, makes another database available for analytics queries and several data sources can be integrated in the final destination, opening path to powerful data crossings.
However, it has other problems, mainly because it greatly increases the complexity of data operations, requiring some development effort to put this data integration from sources to data destination in practice.
Once operational, the ETL flows also become complex to manage, requiring more efforts from specialized people if any changes are necessary.
For example, let's assume that your product has a user registration table and its objective is to know the number of current users of the product. A simple ETL will create a table on the target with only one variable, which is the current number of users, and update this value according to some frequency.
After a while, you see the need to not only count users, but understand their evolution over time. That is: the transformation part of your ETL, which previously only counted the records from the source, now needs to count the grouped records according to the creation date. To make this change, the integration developer will need to change the ETL code, which can take some time to do.
Successful data projects are very dynamic and always need more or less information, making this ETL flow need to be changed several times and overloading the integration developer.
This problem is frequent because of the different skillset of each participant in a data project. The integration developer is a programmer who has mastered the programming language they used to create the ETL and the data consumer is a data scientist/analyst who has mastered SQL or visualization tools and is more focused on understanding business needs and exploring data, having a great need to deal with ALL the available data universe.
ELT: Extract, Load THEN Transform
To avoid this back and forth, the concept of the ELT emerged, which changes the ETL a little, first loading the data into the destination and then transforming it. This means that, while the ETL only raw data already processed in the destination (and needs a developer to change the process), the ELT replicates the raw data from the source to the destination and leaves it in the hands of the analysts and data scientists so that apply the transformations they deem necessary, as they see the needs of the business and its algorithms.
Obviously, the ELT requires more resources from the data target, as that is now where data transformations are performed. However, today the power of available data targets makes ELT a simpler and more agile option to ETL and the perfect choice for the most dynamic data areas.
How does Kondado handle this?
The first step towards this was to simplify the data reading part. Before, you needed to move an engineer from your product team or even hire a developer just for data integration. With Kondado, anyone can create an integration, without having to type a line of code:
Once at the destination, the data can be transformed using our model’s functionality:
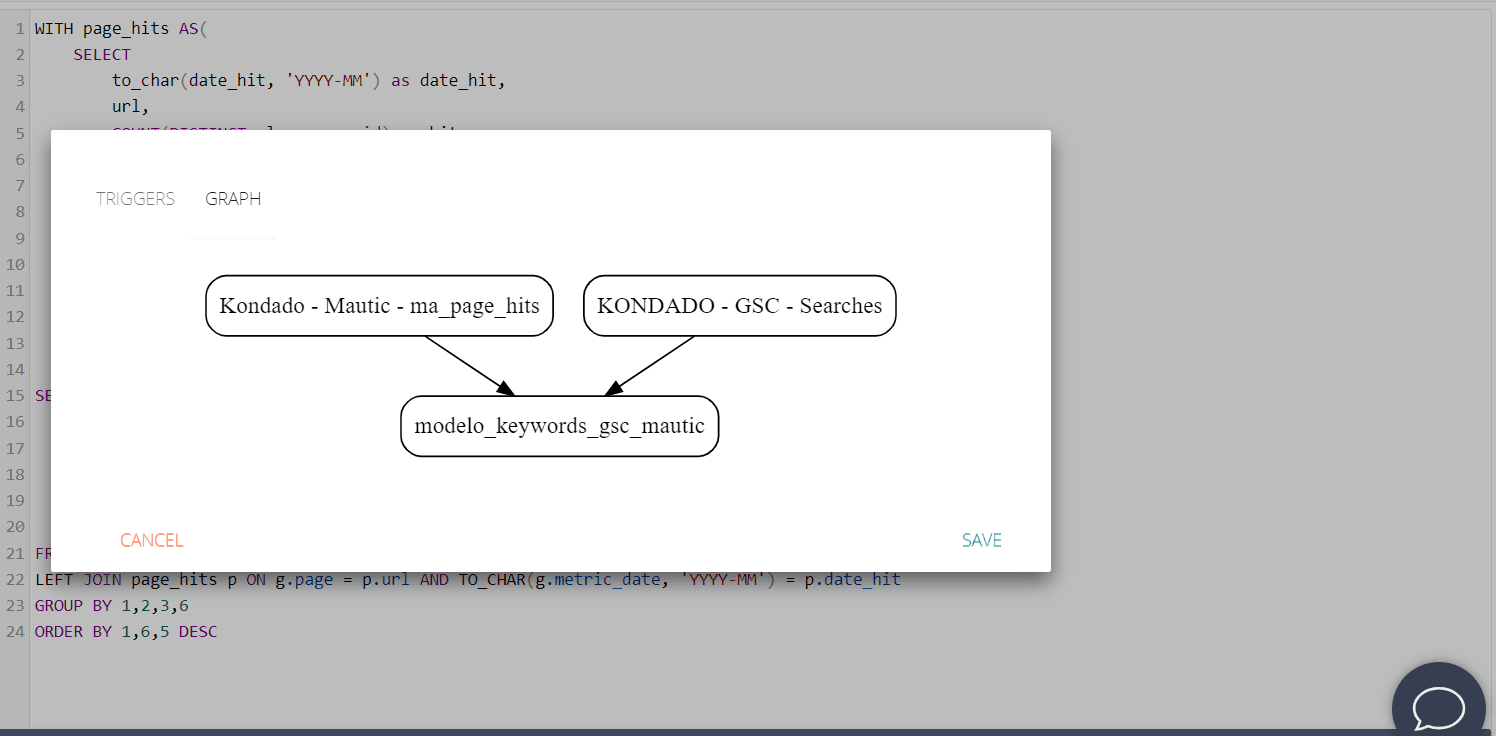
Models
Any scientist or data analyst can create a model, because they are defined VIA SQL, according to the syntax of your data target. In this tutorial we explain how to create models on the Kondado platform.
In addition to making your data flow well-orchestrated, we also facilitate its organization, as the metadata of integrations and models (such as table names, SQLs and column names) are easily queried on our platform, facilitating the traceability of your data.